クラウドでパフォーマンス管理が複雑に
クラウドが検討され始めた当初から常に指摘されていたセキュリティへの懸念に対し、クラウドが実運用の段階になって急速に注目されるようになったのが、パフォーマンス問題と言えるかもしれません。
自社で管理・運用していたシステムをクラウドに移行したところ、期待したほどのパフォーマンスが出ず、クラウドプロバイダにその改善を求 める、というのはありがちな話です。しかし、クラウドで懸念される本当のパフォーマンス問題は、今まで考えられなかったような現象が起こる点にあります。
例えば従来のシステムでは、一旦システムが稼働して安定運用に入ると、新たなサービスの追加、あるいはユーザー数の急激な増加がない限り、パフォー マンスが悪化することはありませんでした。運用する側から見れば、パフォーマンス問題への対応に今までの運用で培ってきた「経験則」で対応することができ ます。
ところがクラウド環境においては、自身のシステムに何ら変更がない場合においても、クラウド側の環境の変化(例えば、クラウドに新たなシステムが追加された場合や、他社システムのユーザー数が増加した場合)によって、パフォーマンスが悪化する可能性があります。
逆にクラウド環境の変化が突然のパフォーマンス改善をもたらすこともありますが、これもITシステムを管理する側からすると大きな問題です。エンド ユーザーに対して一定のサービスレベルの提供が求められるIT部門にとっては、その原因が不明なままパフォーマンスが改善することは何の解決にもならない からです。
問題の本質は、クラウドによってパフォーマンスの変化が予測しづらくなったことです。ではなぜそのようなことが起きるのでしょうか。原因の多くの部分が、仮想化によるものであることは明らかです。
問題の原因は“仮想化の柔軟性”
一口にクラウドと言っても、その中身は、いち企業内に閉じられたプライベートクラウドから、あらゆる企業にオープンなパブリッククラウドまで、その形態はさまざまですが、必ず共通しているのは、「仮想化によって1つの物理マシンが複数のシステムで共有されている」という点です。これは常に自分のシステムが他のシステムの負荷の影響を受けるということを意味します。
さらに仮想化環境ではダイナミックなリソースの移動、あるいはダイナミックなシステムの移動が発生します。これも運用監視の視点からは非常に大きな問題です。従来、オープン系システムの監視は物理マシン単位で行われてきました。例えば、あるスイッチで障害が発生した場合に、その影響が及ぶ範囲は簡単に切り分けることができました。運用上の障害切り分け手順は物理サーバー、ネットワーク機器の物理的な構成に基づいて考えられているため、スイッチの障害による影響範囲は構成図を見れば明らかだったのです。ところが、あるシステムと物理マシンが直接紐づいていない場合、この運用手順を根底から見直す必要があります。ある障害による影響が運用担当者の知らない間に変わってしまう可能性があるのです。
クラウドによっては、サーバーが置いてあるロケーションすら変動したり、あるいはロケーションが明らかでない場合すらあります。このような場合もパフォーマンス管理が大きな懸念事項になるでしょう。
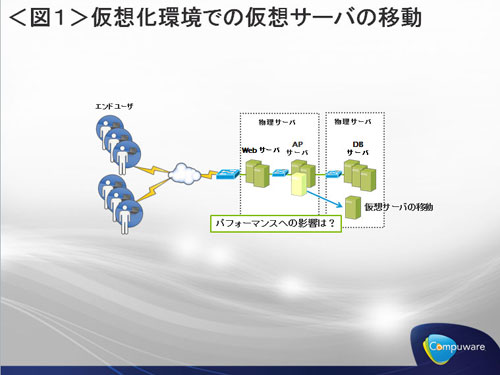
<仮想環境での仮想サーバの移動>
多様化するデバイスも複雑性の一因に
さらにパフォーマンス管理を難しくする要因は仮想化だけではありません。クラウド、仮想化の広がりと歩を合わせるかのように、エンドユーザー端末の多様化が進んでいます。ここ10年以上、エンドユーザー端末と言えばWindowsマシン上で稼動するInternet Explorer(IE)でした。しかし、端末としてPCだけでなく携帯電話、スマートフォン、さらにはiPadに代表される新しいタイプの端末が使われるようになり、ブラウザもIEだけでなく、Firefox、Safari、Operaなど多様化が進みました。端末、ブラウザ、さらにアクセスするネットワークの種類を含めると、そのパターンは100種類以上に及ぶこともあります。これらすべてに対して快適なサービスを提供することは、従来の運用監視方式 では容易ではありません。
いま求められる運用監視とは?
では、現在求められている運用監視とは何でしょう。
みなさんはエンドユーザー体感監視という言葉をご存知でしょうか。ここで言うエンドユーザーとはサービスの利用者、例えばインターネットバンキングであれば自宅のPCからアクセスする一般消費者、企業内のポータルサイトであれば従業員です。これらエンドユーザーがサービスを利用する際、あるページを表示するのに何秒かかるか、これを監視するのがエンドユーザー体感監視です。
いま、このエンドユーザー体感監視の重要性が増しています。
従来、ITシステムの監視はサーバー、ネットワーク機器といった単位で行われてきました。サーバーは立ち上がっているか、CPU使用率は高くないか、ネットワーク機器のポートは立ち上がっているか(Ping監視)など、これらはオープン系のシステムが登場してから長らく行われてきた監視形 態(以下、インフラ監視と呼ぶ)でした。
当然ながら、クラウド環境、仮想化環境になったからといってこれらインフラ監視の重要性が変わるわけではありません。しかし、本来エンドユーザーが快適にサービスを受けられるようにするために行っているはずの監視が、その目的を達していないケースが多く見られます。これは、インフラ監視で検知できる障害とエンドユーザーが体感する障害が必ずしもイコールではないことから生じます。
多様化するデバイスも複雑性の一因に
さらにパフォーマンス管理を難しくする要因は仮想化だけではありません。クラウド、仮想化の広がりと歩を合わせるかのように、エンドユーザー端末の多様化が進んでいます。ここ10年以上、エンドユーザー端末と言えばWindowsマシン上で稼動するInternet Explorer(IE)でした。しかし、端末としてPCだけでなく携帯電話、スマートフォン、さらにはiPadに代表される新しいタイプの端末が使われるようになり、ブラウザもIEだけでなく、Firefox、Safari、Operaなど多様化が進みました。端末、ブラウザ、さらにアクセスするネットワークの種類を含めると、そのパターンは100種類以上に及ぶこともあります。これらすべてに対して快適なサービスを提供することは、従来の運用監視方式 では容易ではありません。
イコールではないシステム障害とエンドユーザー体感
複数のWebサーバーを設置してロードバランサでアクセスを振り分けているようなケースを考えてみましょう。ロードバランシングしているので、Webサーバーのうちの1台がダウンしてもエンドユーザーから見れば何の問題もないかもしれません。しかし、インフラ監視ではWebサーバーのダウンを「深刻な障害」として通知してくるでしょう。
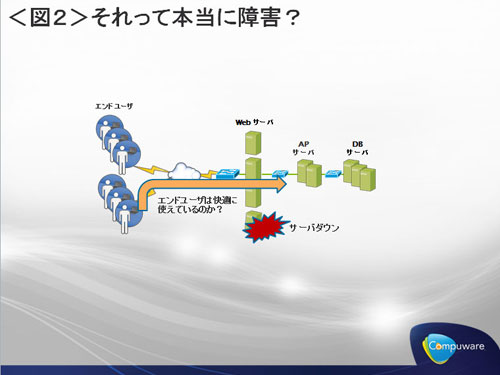
<イコールでないシステム障害とエンドユーザー体感>
一方、インフラ監視では何の障害も通知されないのに、エンドユーザーがサービスを利用できないようなケースは多々あります。例えばネットワーク機器のちょっとした設定変更がシステム全体のパフォーマンスに大きな影響を及ぼすこともあります。この場合、インフラ監視ではシステムに「問題なし」と判断するでしょう。
こうした乖離(かいり)は、今までの監視方式の延長では解消できません。どんなにサーバーの監視を細かく行っても、「エンドユーザーが快適に利用できている」という本来の目的を満たすことはできないのです。逆にサーバーやネットワーク機器の稼働状態に関する情報、レポートが多すぎて、集めるだけ集めて全く使われていない、あるいはその情報の整理に時間をとられ、運用負荷が高くなっている、といった本末転倒な状態に陥りがちです。
エンドユーザー体感監視の有効性
これを解決するべく登場したのがエンドユーザー体感監視です。今から10年ほど前、企業の基幹システムにWeb、インターネットの利用が普及した際、エンドユーザー体感監視が広く採用されました。それまでエンドユーザーはクライアントアプリケーションをインストールし、サーバーへはLANまたは専用線など安定した回線を利用していたのが、Webシステムへの移行に伴いネットワークとしてインターネットを使うようになり、パフォーマンスの問題が頻発しました。これを解決する方法としてエンドユーザーの視点からパフォーマンスを監視する必要性が認識されました。
クラウド・仮想化が普及しつつある現状は当時とよく似ています。環境が大きく変化することによって、再びエンドユーザー体感監視の重要性が増してきたのです。
クラウド、仮想化という視点から、エンドユーザー体感監視導入によるメリットは大きく分けて2つあります。ひとつはビジネスサイドへのメリットとして「サービスレベルの可視化」が実現すること、もうひとつは運用現場へのメリットとして「運用の効率化」が挙げられます。
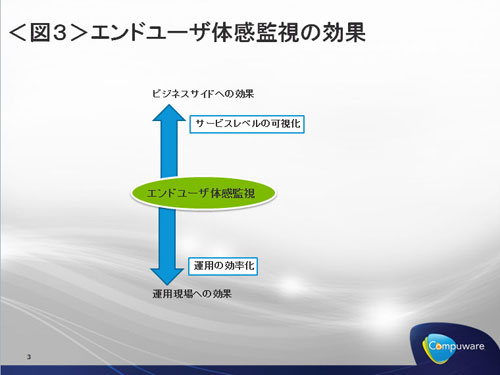
<エンドユーザー体感監視の効果>
メリット1:サービスレベルの可視化
今まで見てきたように、クラウドと仮想化は確実にパフォーマンス上の懸念をもたらします。利用者から見れば、それが重要なシステムであるほど安定したパフォーマンスが提供されていること、さらにそれが保証されていることがクラウド選びの条件になります。
クラウドプロバイダ側から見れば、快適なパフォーマンスを常に提供できていることを監視し、さらにそれを利用者にサービスレベル情報として提供することは、自分たちのサービスの安定性、あるいはパフォーマンスの良さを示す最適な手段となります。
サービスレベル管理の重要性は昔から言われ続けてきましたが、今までなかなか日本では根付きませんでした。情報システム部がきちんとやってくれているはず、SIerに任せているから、といった曖昧な状態が続いていました。しかしクラウドの広がりはこれを許さなくなりつつあります。安定的なパフォーマンスの提供が難しいサービス形態であるからこそ、サービスレベル管理の重要性が見直されてきているのです
なお、一般的に欧米系のクラウドプロバイダに比べて、日本のクラウドプロバイダはサービスレベル管理の導入に積極的なようです。これは比較的安価なクラウドサービスに、サービスレベル管理という付加価値で対抗しようという意図があると思われます。実際、今後企業の重要なシステムがクラウドに移行していく中で、サービスレベル管理はより一般的になっていくでしょう。
メリット2:運用の効率化
上記のとおり、クラウド、仮想化は運用監視手法に新しい課題をもたらします。つまり、個々のサーバー、ネットワーク機器の監視の積み上げでは、運用監視に要する作業の効率が悪くなります。サービスとサーバーの関係が固定ではないため、あるサーバーの障害がどのサービスに影響を及ぼすのか、あるいは逆にあるサービスのパフォーマンス悪化の原因がどのサーバー、どのネットワークにあるのか、その判断が非常に難しくなるのです。
エンドユーザー体感監視の導入によってこの問題は大きく改善するでしょう。パフォーマンスの問題が発生したとき、まずエンドユーザー体感監視で得られた情報に基づき、その問題の影響範囲、重要度、そして場合によってはそもそも本当に問題が起こっていたのか、といった切り分けを行います。その上で問題の原因分析に入っていくのです。エンドユーザー体感監視による初期分析を行うことによって、問題解決までに要する時間と労力は劇的に削減される でしょう。この点については本連載の次回以降で詳しく説明します。
連載第1回目の今回は、クラウド環境でいかにパフォーマンスの管理が難しくなるか、そしてその対策としてエンドユーザー体感監視がいかに有効か説明しました。次回以降でエンドユーザー体感監視の具体的な機能や効果について紹介していきたいと思います。
※本内容は、日本コンピュウェアが作成し、2011年3月30日付で「クラウドWatch」に掲載されたものです。
※本内容に掲載されている文章や図などを日本コンピュウェアに無断で転載することを禁じます。